二项树(Binomial Tree)
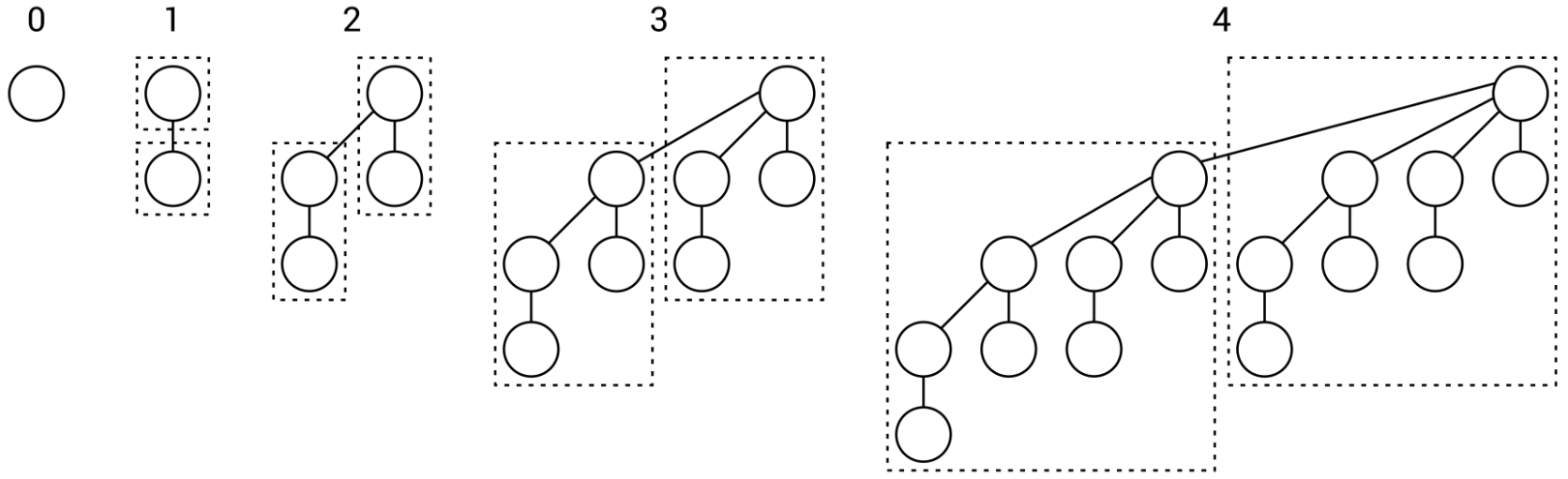
二项树的形态是递归定义的,通常用\(B_k\)表示每种二项树形态,其中\(B_0\)仅包含树根节点,\(B_k\)可通过连接2个\(B_{k-1}\)得到,连接方式是在2个\(B_{k-1}\)间额外加1条树边,使其中一个\(B_{k-1}\)成为另一个\(B_{k-1}\)的最左子树,具体可参考上图。注意到该定义表明二项树必须是有序树,另外二项树通常更适合用孩子兄弟表示法实现。下面给出关于二项树的重要性质:
a1) \(B_k\)形态的二项树共包含\(2^k\)个节点;
证明:将二项树形态对应的节点数计为\(n(B_k)\),则有\(n(B_k)=2n(B_{k-1})=…=2^kn(B_{0})=2^k\)。
a2) \(B_k\)形态的二项树的高度为\(k+1\);
证明:将二项树形态对应的高度计为\(h(B_k)\),则有\(h(B_k)=1+h(B_{k-1})=…=k+h(B_{0})=k+1\)。
a3) \(B_k\)形态的二项树的树根的出度为\(k\),并且树根从左到右的子树的形态分别是\(B_{k-1},B_{k-2},…,B_0\);
证明:树根的孩子都“通过连接得到”,从左到右分别是“2个\(B_{k-1}\)的连接”、“2个\(B_{k-2}\)的连接”、…、“2个\(B_{0}\)的连接”。
a4) \(B_k\)形态的二项树在第\(i\)层有\(C_k^{i-1}\)个节点(\(0 < i \leq k+1\));
证明:将\(B_k\)第\(i\)层的节点数计为\(D(k,i)\),则有\(D(k,1)=1\)并且根据(a3)有\(D(k,2)=k\),当\(i>2\)时根据2个\(B_{k-1}\)的高度关系容易得到递推式\(D(k,i)=D(k-1,i-1)+D(k-1,i)\)。注意到\(C_k^{0}=1,C_k^{1}=k\)并且有\(C_k^{i}=C_{k-1}^{i-1}+C_{k-1}^{i}\)的组合数公式,于是可假设\(i>2\)时有\(D(k,i)= C_k^{i-1}\),然后走一遍数学归纳法的流程即可证明\(D(k,i)= C_k^{i-1}\)。
a5) 对于包含\(n>0\)个节点的二项树,其中任意节点的出度都不超过\(\log_2{n}\);
证明:这是(a1)(a3)的推论,在\(B_k\)中显然树根出度最大,而其他节点(子树)虽然是二项树但规模都不大于\(B_k\)。
二项堆(Binomial Heap)
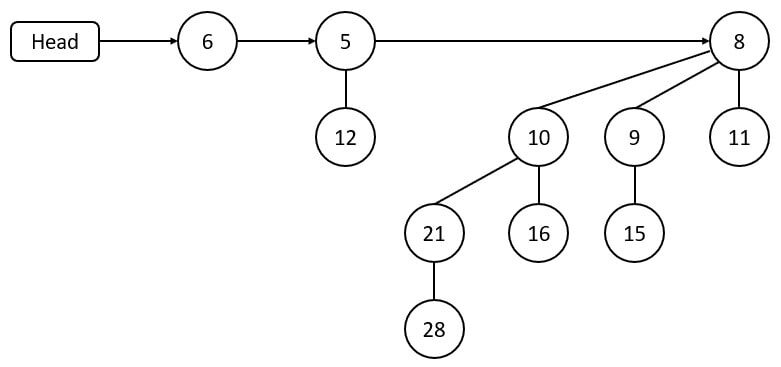
1978年法国学者Jean Vuillemin提出二项堆,这是种基于二项树的堆。二项堆本身的定义就是一组满足堆性质的形态无重复的独立二项树。在通用的二项堆表示法中,二项堆中的每个独立二项树都采用孩子兄弟表示法,由于独立二项树的树根没有兄弟,所以利用这些兄弟指针将这些树根按出度升序连成链表,该链表被称为根表(root table)。上图是这种二项堆的例子。在具体实现时除了要在节点存储关键字\(key\),还会存储节点的父亲\(parent\)和出度\(degree\)。这里给出二项堆的重要性质如下:
b1) 对于包含\(n\)个节点的二项堆,\(n\)的二进制数的第\(k\)位等于该二项堆中\(B_{k-1}\)形态的独立二项树的数目;
证明:将\(n\)的二进制数的第\(k\)位计为\(a_k\),根据二进制数的定义有\(n=\sum_{i=1}^{\infty} a_i2^{i-1}\)。将该二项堆中的\(B_{k-1}\)形态独立二项树的数目计为\(b_k\),则根据(a1)有\(n=\sum_{i=1}^{\infty} b_i2^{i-1}\),根据二项堆的定义\(b_k\in \{0,1\}\),由于整数的二进制数表示唯一,所以\(a_k=b_k\)。
b2) 对于包含\(n>0\)个节点的二项堆,其中的独立二项树的数目不大于\(\lfloor\log_2{n}\rfloor+1\);
证明:根据二进制数的定义\(n\)的二进制数是\(\lfloor\log_2{n}\rfloor+1\)位数,所以\(n\)的二进制数中至多包含\(\lfloor\log_2{n}\rfloor+1\)个等于1的位。最后根据(b1)可知该二项堆中至多包含\(\lfloor\log_2{n}\rfloor+1\)个独立二项树。
上述(b1)表明二项堆具有“二进制数计数器”的特殊性质,这也间接证明二项堆的节点数可以是任意自然数。在讨论数据结构时通常没有必要单独论证其能否容纳任意个元素,因为在构造运算时就必须根据该数据结构的定义预先假设所有的可能情况,只要能构造出正确的运算就能间接验证这一点。最后给出二项堆需要实现的运算如下,二项堆也属于可并堆:
1) \(merge(h_1,h_2)\):将分别以\(h_1,h_2\)为根表表头的2个二项堆合并成1个二项堆,然后返回该二项堆的根表表头;
2) \(put(k)\):在二项堆插入一个等于\(k\)的关键字;
2) \(minimum()\):返回二项堆的其中一个最小关键字节点;
4) \(get()\):从二项堆去掉其中一个最小关键字节点并返回它;
5) \(decrease(x,k)\):将二项堆的其中一个等于\(x.key\)的关键字更新为\(k<x.key\);
6) \(delete(x)\):从二项堆中去掉其中一个等于\(x.key\)的关键字;
需注意到上述运算大多针对节点而非关键字,其中\(decrease(x,k)\)和\(delete(x)\)又并不要求作用于节点\(x\)本身。
二项堆的运算
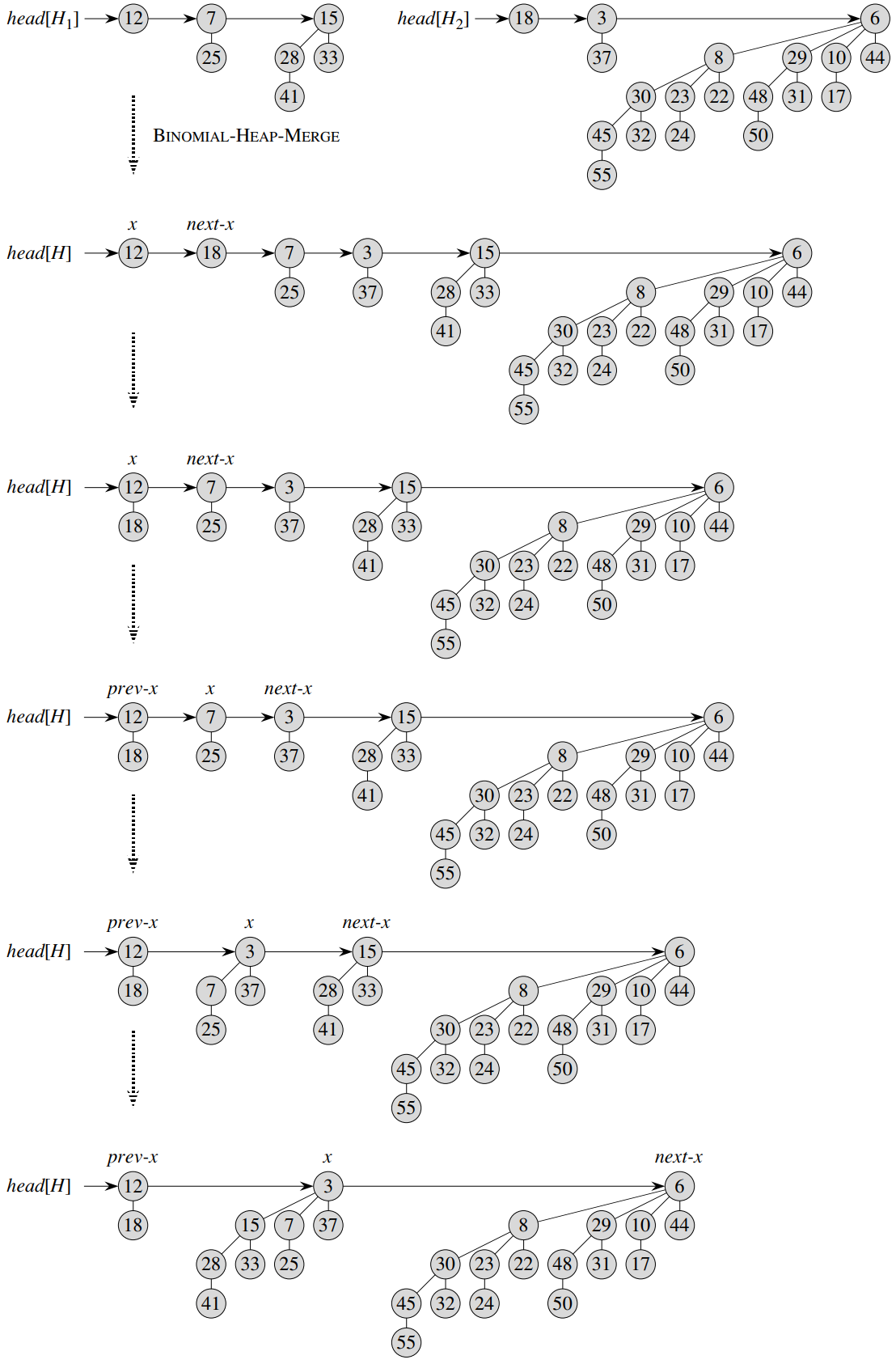
由于上述各种运算的主要步骤都是对\(brother\)链表的操作,所以这里首先明确一种被称为哑节点法(dummy node)的构造链表操作的通用技巧。该技巧是先在原表头前插入新节点\(dummy\),这样原表头就成为新表头\(dummy\)的后继,然后再构造链表操作并且最后将\(dummy\)的后继作为操作结束后的链表。该技巧能保证所有原节点都有前驱,从而能统一对不同原节点的操作步骤,比如对于“删除节点\(x\)”操作,无论\(x\)是否为表头其都有前驱\(y\),都能通过置\(y.next=x.next\)完成删除。
接下来构造最关键的\(merge\)运算。该运算可分解成几个互相独立的操作,所以可通过如下操作给出\(merge\)的步骤:
1) \(mergeList(h_1,h_2)\):首先创建一个哑节点并且初始化\(h,dummy\)都指向该哑节点,接下来开始一个迭代过程。在每轮迭代中若\(h_1\)为空,则置\(h.brother=h_2\),返回\(dummy.brother\)。否则若\(h_2\)为空,则置\(h.brother=h_1\),返回\(dummy.brother\)。否则若\(h_1.degree<h_2.degree\),则置\(h.brother=h_1\),然后置\(h=h.brother\),然后置\(h_1=h_1.brother\),继续执行下轮迭代。否则置\(h.brother=h_2\),然后置\(h=h.brother\),然后置\(h_2=h_2.brother\),继续执行下轮迭代;
2) \(linkTree(prv)\):首先初始化\(x=prv.brother,y=prv.brother.brother\)。若\(x.key>y.key\),则置\(prv.brother=y\),然后置\(p=y, c=x\)。否则置\(x.brother=y.brother\),然后置\(p=x, c=y\)。接着置\(c.brother=p.child\),然后置\(p.child=c\)。最后置\(c.parent=p\),置\(p.degree=p.degree+1\);
3) \(fixList(h)\):首先创建一个哑节点并且初始化\(prv,dummy\)都指向该哑节点,然后置\(prv.brother=h\),接下来开始一个迭代过程。在每轮迭代中若\(h\)为空或者\(h.brother\)为空,则直接返回\(dummy.brother\)。否则若\(h.degree < h.brother.degree\),则置\(prv=h,h=h.brother\),继续迭代。否则若\(h.brother.brother\)为空,则执行\(linkTree(prv)\),返回\(dummy.brother\)。否则若\(h.brother.degree < h.brother.brother.degree\),则执行\(linkTree(prv)\),然后置\(h=prv.brother\),继续迭代。否则执行\(linkTree(h)\),然后置\(prv=h,h=h.brother\),继续迭代;
4) \(merge(h_1,h_2)\):置\(h=mergeList(h_1,h_2)\),返回\(fixList(h)\);
简单验证\(merge(h_1,h_2)\)步骤的正确性。其中\(mergeList(h_1,h_2)\)能够按节点出度的非严格升序合并两个根表,其核心思路是每次都对比这两个根表的当前表头,取下两者中最小出度的追加到新表中,直到其中一个根表为空则直接将另一个根表整个追加到新表中。在执行完置\(h=mergeList(h_1,h_2)\)后,表头为\(h\)的根表上可能存在相同形态的独立二项树,但每种形态的独立二项树至多存在2个。\(linkTree(prv)\)执行前需保证\(prv,prv.brother,prv.brother.brother\)都不为空,并且后2者形态相同,其执行结束后原\(prv.brother,prv.brother.brother\)被合并,合并后的二项树满足堆性质且位于根表原来的位置。\(fixList(h)\)运算则是整个过程中最核心的步骤,其能够通过调用\(linkTree\)使表头为\(h\)的根表中无相同形态的独立二项树。这里通过循环不变式的思路简单分析\(fixList(h)\)的正确性,首先注意到执行\(linkTree\)可能导致根表上存在3个形态相同的独立二项树,
总结与实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 | class Node: def __init__(self, key): self.key = key self.degree = 0 self.child = None self.brother = None self.parent = None class BinomialHeap: def __init__(self): self.head = None @staticmethod def _mergeList(h1, h2): h = dummy = Node(0) while True: if not h1: h.brother = h2 return dummy.brother if not h2: h.brother = h1 return dummy.brother if h1.degree <= h2.degree: h.brother = h1 h = h.brother h1 = h1.brother else: h.brother = h2 h = h.brother h2 = h2.brother @staticmethod def _linkTree(prv): x, y = prv.brother, prv.brother.brother if x.key > y.key: prv.brother = y p, c = y, x else: x.brother = y.brother p, c = x, y c.brother = p.child p.child = c c.parent = p p.degree += 1 @classmethod def _fixList(cls, h): prv = dummy = Node(0) prv.brother = h while True: if not h or not h.brother: return dummy.brother elif h.degree < h.brother.degree: prv, h = h, h.brother elif not h.brother.brother: cls._linkTree(prv) return dummy.brother elif h.brother.degree < h.brother.brother.degree: cls._linkTree(prv) h = prv.brother else: cls._linkTree(h) prv, h = h, h.brother @classmethod def merge(cls, h1, h2): return cls._fixList(cls._mergeList(h1, h2)) def put(self, k): x = Node(k) self.head = self.merge(self.head, x) return x # 返回新加入的节点 # 返回brother链表上其中一个最小关键字的节点及其前驱 @staticmethod def _minimum(h): targetPrev, target = None, h prv = None while h: if h.key < target.key: targetPrev, target = prv, h prv, h = h, h.brother return targetPrev, target def minimum(self): _, r = self._minimum(self.head) return r # 反转brother链表并将每个节点的parent置空 @staticmethod def _reverseAndRemoveParent(h): newHead = None while h: h.parent = None tmp = h.brother h.brother = newHead newHead = h h = tmp return newHead def get(self): if not self.head: return None prv, r = self._minimum(self.head) if prv: prv.brother = r.brother else: self.head = r.brother h = self._reverseAndRemoveParent(r.child) self.head = self.merge(self.head, h) return r # 返回去掉的节点 def decrease(self, x, k): assert k < x.key x.key = k while x.parent and x.key < x.parent.key: x.key, x.parent.key = x.parent.key, x.key x = x.parent return x # 返回最终关键字等于k的节点 def delete(self, x): while x.parent: x.key, x.parent.key = x.parent.key, x.key x = x.parent prv, h = None, self.head while h: if h is x: if prv: prv.brother = x.brother else: self.head = x.brother break prv, h = h, h.brother h = self._reverseAndRemoveParent(x.child) self.head = self.merge(self.head, h) return x # 返回实际被去掉的节点 def test(size): import heapq from random import randint, choice def traverse(h): result = [] while h: result.append(h) result += traverse(h.child) h = h.brother return result def checkDegree(h): count = 0 while h: count += 1 n = checkDegree(h.child) assert n == h.degree h = h.brother return count def checkParent(h, p): while h: assert h.parent is p checkParent(h.child, h) h = h.brother h = BinomialHeap() arr = [] for _ in range(size): if randint(0,1) == 0 or not h.head: k = randint(0,1) x = h.put(k) heapq.heappush(arr, k) else: x = choice(traverse(h.head)) k = randint(x.key-1000, x.key-1) arr.remove(x.key) arr.append(k) heapq.heapify(arr) y = h.decrease(x, k) assert y.key == k assert sorted([i.key for i in traverse(h.head)]) == sorted(arr) print(checkDegree(h.head), len(arr)) checkParent(h.head, None) while h.head: x = choice(traverse(h.head)) arr.remove(x.key) heapq.heapify(arr) h.delete(x) assert sorted([i.key for i in traverse(h.head)]) == sorted(arr) print(checkDegree(h.head), len(arr)) checkParent(h.head, None) test(10000) |
要求包含原本的所有独立二项树并使它们按树根的出度非严格升序排序,但不要求二项树的形态唯一,最后需返回其表头。具体步骤是先创建一个哑节点,并初始化\(h,dummy\)都指向它,然后开始一个迭代过程,在每轮迭代若\(h_1\)为空则置\(h.brother=h_2\),返回\(dummy.brother\)。否则若\(h_2\)为空则置\(h.brother=h_1\),返回\(dummy.brother\)。
从而得到1个按节点出度非严格升序排序的“根表”(可能包含重复的二项树形态),最后返回其表头。
1) \(mergeTree(r_1,r_2)\):将以\(r_1,r_2\)为树根的2个非空的\(B_k\)形态的满足堆性质的二项树连接,从而得到1个\(B_{k+1}\)形态的满足堆性质的二项树,最后返回该二项树的树根。具体步骤是若\(r_1.key>r_2.key\)则交换\(r_1,r_2\)的指向,然后置\(r_2.brother=r_1.child\),然后置\(r_1.child=r_2\),然后置\(r_2.parent=r_1\),最后返回\(r_1\);
2) \(mergeList(h_1,h_2)\):将以\(h_1,h_2\)为表头的2个二项堆的根表的所有节点合到一起,从而得到1个按节点出度非严格升序排序的“根表”(可能包含重复的二项树形态),最后返回其表头。
3) \(fixList(h)\):
合并为1个按照节点出度非严格升序排序的链表,
首先很容易直接构造上述的\(minimum,decrease\)运算。其具体步骤如下:
1) \(minimum()\):遍历根表找到并返回其中有最小关键字的节点;
2) \(decrease(x,k)\):首先置\(x.key=k\)。然后开始一个迭代过程,在每轮迭代若\(x.parent\)存在且\(x.parent.key>x.key\),则交换\(x.key\)与\(x.parent.key\),然后置\(x=x.parent\)并继续迭代,否则退出迭代返回;
然后来构造\(merge\)运算。
首先考虑将\(r_1,r_2\)根表合并为\(r\)为根表,这里仅要求\(r\)根表包含原\(r_1,r_2\)根表的全部节点并将它们按出度非严格升序排序,暂不要求\(r\)根表上的各个独立二项树无重复的形态。实现这一点仅需迭代的比较\(r_1,r_2\)根表的当前表头,取下其中出度更小的追加至\(r\)根表的后面即可。接下来考虑如何使\(r\)根表上的各个独立二项树无重复的形态。首先注意到对于任意一种二项树的形态,\(r\)根表上至多有2个独立二项树使用该形态,但如果将2个形态都为
\(r\)根表中
无出度重复的节点。首先注意到在\(r\)根表中,对于任意出度值\(k\),至多有2个节点的出度等于\(k\),但如果
合并为按出度非严格升序排序的根表,
为方便描述先定义\(mergeLL(r_1,r_2)\)操作用于将以\(r_1,r_2\)为表头的根表合并为按出度非严格升序排序的根表(允许重复),并返回其表头。然后定义\(fixLL(r)\)操作用于将
这里将其拆分为\(mergeLL(r_1,r_2)\)和\(_fixLL(r)\)两个操作,
上述其他运算都基于\(merge(r_1,r_2)\)运算,所以这里构造
其可分两步来完成,第一步是将\(r_1,r_2\)合并成1个按出度非严格升序排序的表头为\(r\)的链表
其具体步骤和相关的说明如下:
1) \(merge(r_1,r_2)\):先将\(r_1,r_2\)合并成1个按出度非严格升序排序的表头为\(r\)的链表,而这只需迭代的比较\(r_1,r_2\)的当前表头并取下其中出度更小的追加至\(r\)为表头的链表即可。其具体步骤是先创建一个哑节点(dummy node)以简化步骤,并且初始化\(r,r’\)都指向该哑节点,然后开始一个迭代过程,
首先讨论最基础的合并运算,合并运算是把两个二项堆链表合成新链表,第一步是按归并排序合并两个子序列的方式得到树根出度递增排序的新链表。此时对于任意整数\(a \geq 0\),新链表至多有两个节点出度等于\(a\)。故该链表有可能违反上述二项堆性质(2),所以需要遍历该新链表去维护二项堆性质(2)。设\(x\)为当前链表节点并分情况讨论:
1) \(x\)的出度小于\(x.next\):此时只需把\(x\)后移为\(x.next\),然后继续遍历;
2) \(x\)的出度等于\(x.next\)且\(x.next\)的出度小于\(x.next.next\):此时需要把\(x\)与\(x.next\)合并成新的小根堆,这只需比较两个树根把大树根作为小树根的左子树即可,最后把\(x\)指向该小根堆,然后继续遍历;
3) \(x\)的出度等于\(x.next\)且\(x.next\)的出度等于\(x.next.next\):这种3个相同出度节点的情况发生于步骤(2)或(3)之后。此时需把\(x.next\)与\(x.next.next\)合为新小根堆。最后把\(x\)指向该小根堆,然后继续遍历;
然后以合并运算为基础构造上文中的其他运算结构:
\(push(k)\):把\(k\)初始化为只有单树单节点的堆,然后合并两个堆即可;
\(minimum()\):在二叉堆链表上遍历最小关键字节点并返回;
\(pop()\):先执行\(minimum()\)返回树根\(B\),根据二项树性质(4)该树根的下层节点从右到左刚好形成出度递增并唯一的链表\(L\)。这样原运算转化为“把原链表中的\(B\)节点删除后再与\(L\)链表执行合并”;
\(decrease(X,k)\):该运算与二叉堆上的该运算基本相同,把节点\(X\)的关键字更新为\(k\),然后向二项树的树根回溯,若当前节点的关键字小于父节点的关键字就交换二者关键字,然后继续回溯。否则退出回溯;
\(delete(X)\):执行\(decrease(X,(minimum().key-1))\)让\(X\)上升为某二项树树根,然后执行\(pop()\)即可;
具体实现
在实现时要考虑如何同时表示二项树与链表,这里采用有序树的“孩子-兄弟(child-sibling)表示法”,且每个二项树节点都有父指针。这样一来二项堆链表节点可以复用二项树节点,用sibling来表示链表指针,但其父指针为空。另外需要注意的是该实现中\(decrease\)在处理节点“上浮”时并未交换节点对象本身,而是采用了交换\(key\)的方法,所以每次执行\(decrease\)都“不可预料”的改变若干节点对象的\(key\),比如我们遍历得到二项堆的节点对象序列,如果在这之后执行了\(decrease\),那么这个序列可能会“失效”。但如果通过交换节点对象来实现\(decrease\)运算,则不会有上述的问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 | class Node: def __init__(self,key): self.key = key self.degree = 0 self.child = None self.sibling = None self.parent = None class BinomialHeap: @staticmethod def _reverse(x): # 反转二项树sibling链表并移除parent指针 if not x: return None y = x.sibling x.sibling = None while y: r = y.sibling y.sibling = x x = y y = r _x = x while x: x.parent = None x = x.sibling return _x @staticmethod def _remove(h,x): # 给定链表表头h删除节点x并返回新表头 n = h p = None while n: if x == n: if p: p.sibling = n.sibling return h else: return h.sibling p = n n = n.sibling @classmethod def _merge(cls,x,y): # 合并按degree排序的链表为新的按degree排序的链表 if not(x and y): return x if x else y if x.degree < y.degree: x.sibling = cls._merge(x.sibling,y) return x else: y.sibling = cls._merge(x,y.sibling) return y @staticmethod def _link(x,y): # 把小根堆y合并到小根堆x y.parent = x y.sibling = x.child x.child = y x.degree += 1 def __init__(self): self.head = None def minimum(self): # 返回链表最小key节点 h = self.head m = self.head while h: if m.key > h.key: m = h h = h.sibling return m def union(self,y): # 合并两个二项堆链表为新的二项堆链表 if not self.head: self.head = y return if not y: return self.head = self._merge(self.head,y) x = self.head prv = None nxt = x.sibling while nxt: if x.degree != nxt.degree: prv = x x = nxt elif nxt.sibling and nxt.sibling.degree == x.degree: prv = x x = nxt elif x.key <= nxt.key: x.sibling = nxt.sibling self._link(x,nxt) else: if not prv: self.head = nxt else: prv.sibling = nxt self._link(nxt,x) x = nxt nxt = x.sibling def push(self,k): self.union(Node(k)) def pop(self): if not self.head: return None x = self.minimum() self.head = self._remove(self.head,x) y = self._reverse(x.child) self.union(y) return x.key def decrease(self,x,k): x.key = k while x.parent: if x.key >= x.parent.key: break ( x.key, x.parent.key ) = ( x.parent.key, x.key ) x = x.parent def delete(self,x): self.decrease(x,-float('inf')) self.pop() |